

🕷️ ScrapeWave: Web Scraping using Puppeteer in a Docker container with a UI dashboard and database.

🕷️ ScrapeWave project was created to help me accomplish some scraping tasks.
The requirements of the task I was building were:
To be able to access a particular link.
Parse the content of the page and save it somewhere.
Log error in case something unexpected happens.
Ability to start and stop the scarping.
Ability to add more data into the tool.
Ability to import and export data into and from the tool.
And, provide a UI for the person who is administering the tool to be able to see the progress.
Easy & quick to deploy multiple instances of it.
This project uses multiple technologies to achieve the requirement.
Server
ViteExpress - @vitejs integration module for @expressjs.
SQlite - SQLite client wrapper around sqlite3 for Node.js applications with SQL-based migrations API written in Typescript.
Puppeteer - Node.js API for Chrome
https://github.com/socketio/socket.io - Realtime application framework (Node.JS server).
Other packages worth mentioning are:-
axios
fast-csv
UI
Docker - Accelerated Container Application Development
ScrapeWave in action
Adding data to your tool
Using CSV import you can add data to your scarper.
Head over to upload the page and upload the data.
You can use the sample.csv file attached to the repository.
As you can see we have three data which can be seen in the table at home.

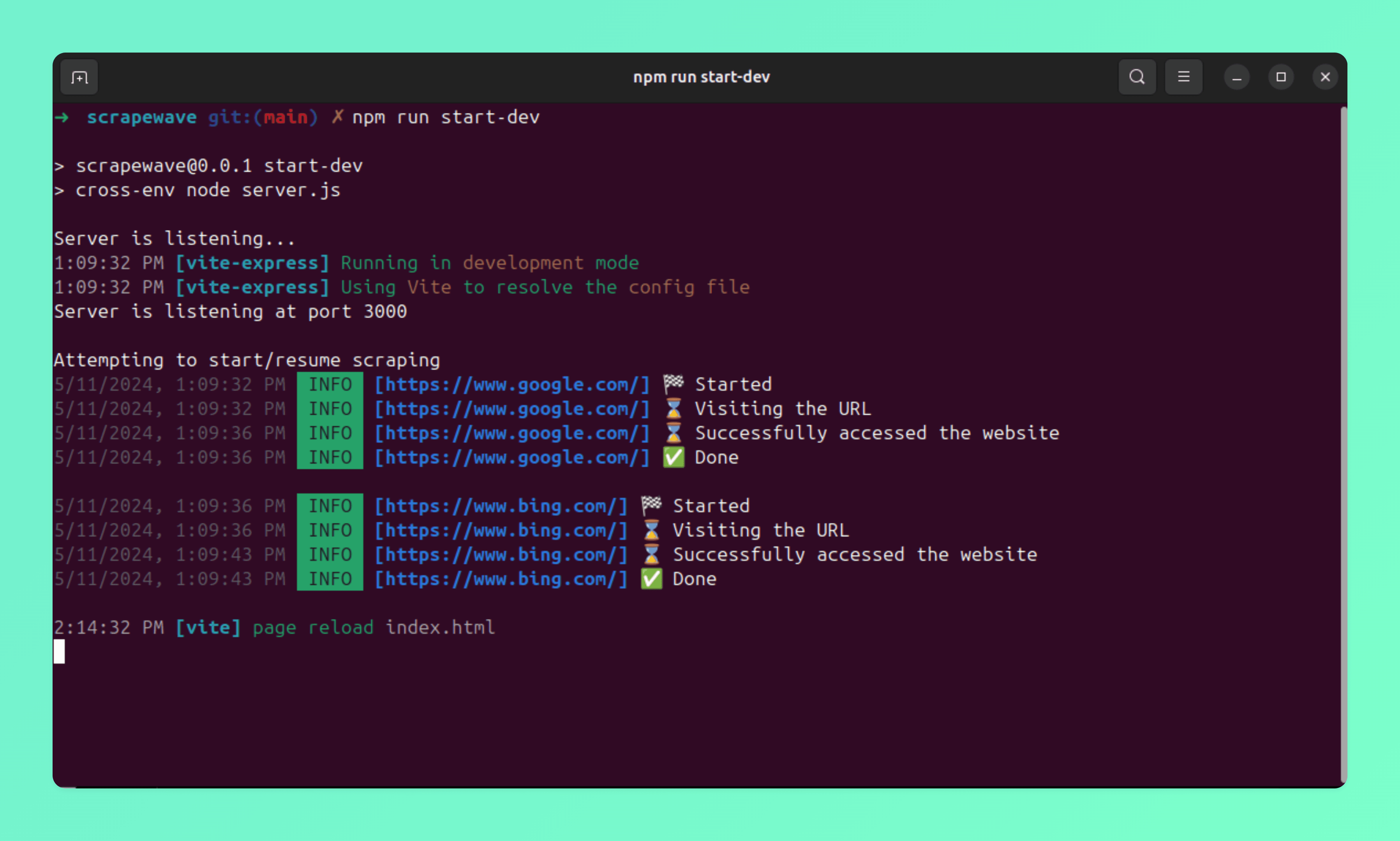
Starting the script
You can start the scraping process by clicking on the start button on the home page.

As you can see from the image above scraping for the first two entries is done. We also nice logs in your terminal which shows the current status of the software.
Deploying ScrapeWave in Cloud
Once you have created the changes as per your liking in the project (learn how to do that from the readme file of the repo) you can create a docker image.
You can name the image whatever you want.
docker build -t bhanu/scrapewave:latest .
Here, bhanu would be the docker hub username and scrapewave is the name of the image.
You can push the image to your docker hub using the following command.
Make sure you are logged in your dokcer hub account.
dokcer push bhanu/scrapewave:latest
Once it is done, go to the server using ssh and install two software, docker and Nginx.
- To install Docker follow the steps here:
- To install Nginx follow the steps here:
https://www.digitalocean.com/community/tutorials/how-to-install-nginx-on-ubuntu-18-04
Once you have successfully installed both,
You can use docker run -dit --name <instance-name> -p <port>:3000 krenovate/data-validator:latest to create a container.
For eg.
docker run -dit -v instance-1:/usr/src/app/db --name instance-1 -p 8080:3000 --restart on-failure bhanu/scrapewave:latest
This command does quite a few things:
Creates a container using
latesttag ofbhanu/scrapewaveMounts the SQlite database in your host filesystem, ensuring even if you recreate the the container with
instance-1volume your data would still be persistent.For any scenario if the container exists, it will try to restart the container so that your scraping doesn't stop.
I plan to keep on improving this project so that it helps me and other folks to use it as the base to get up and running with there scraping task.
Feel free to raise issues if you see anything which is broken - https://github.com/git-bhanu/scrapewave/issues
Also any kind of contribution is appreciated.
![How to Upgrade to a non-LTS Ubuntu [23.10] ?](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1712845921509%2F0d9f625a-85da-4e09-939e-121780145fd5.jpeg&w=3840&q=75)

